All posts
-

Data-driven detection of gas leakages in high-voltage equipment
Gas Insulated Switchgear (GIS) is a type of high-voltage equipment where key electrical components are enclosed in sealed compartments filled with insulating gas. The insulating gas is typically sulfur hexafluoride (SF₆), a very potent greenhouse gas. Monitoring the gas compartments is therefore essential, not only to ensure correct operation of critical components, but also to address a significant environmental concern.… Read more
-
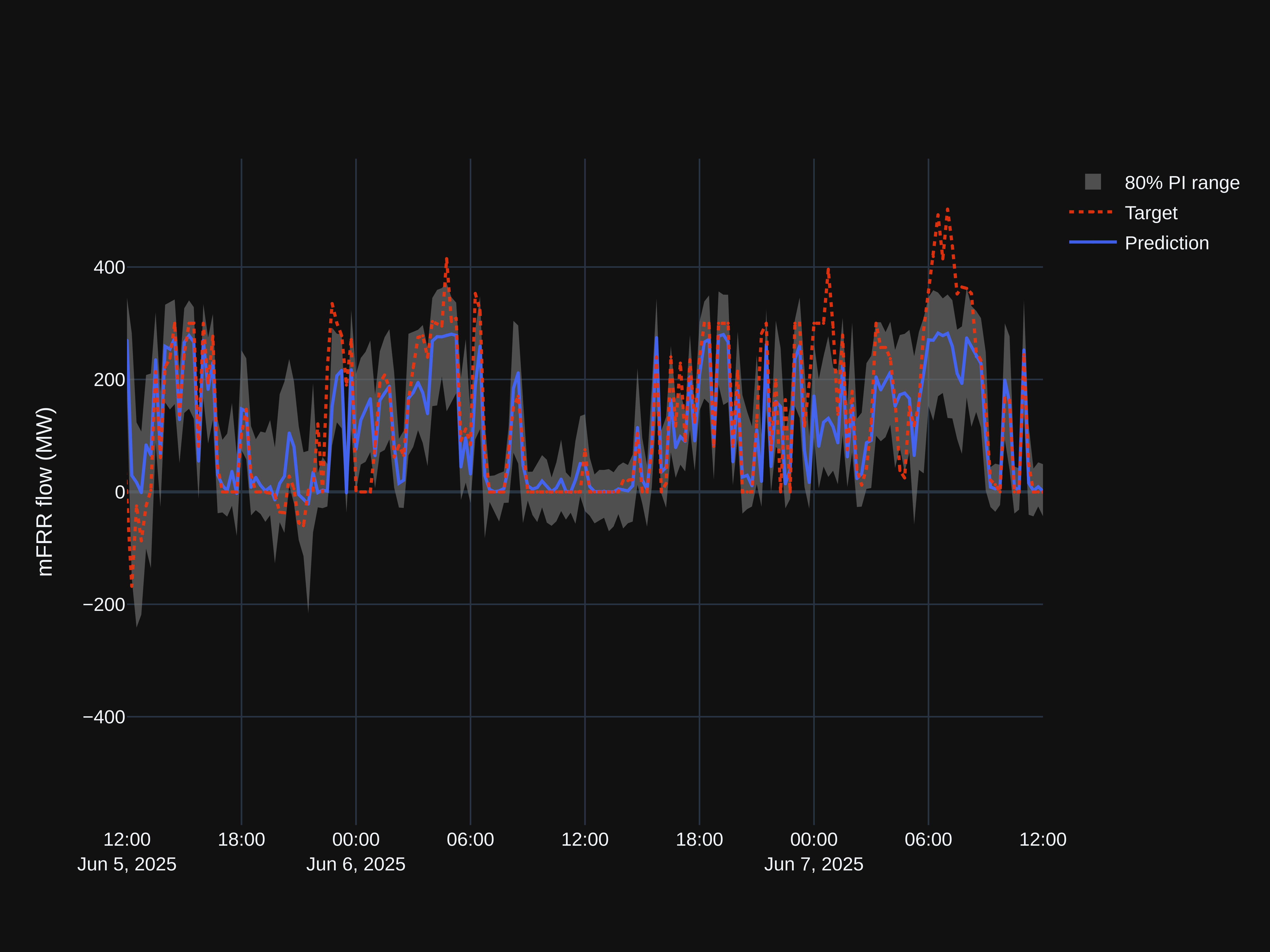
Quantifying uncertainty in forecasts – methods and lessons from mFRR flow prediction
Point forecasts tell us what might happen; uncertainty tells us how much to trust them. In this blog post we will compare different methods of probabilistic forecasting. While there are methods that produce a full probability distribution, we focus on methods that can generate prediction intervals to go along with a point forecast. Read more
-

From 10,000 Manual Checks to Continuous Insight
TL; DR: We are automating voltage transformer (VT) maintenance by linking CIM model context with time series analysis and lightweight apps. In the future we expect fewer manual site checks, earlier detection of issues, and continuous visibility across substations—without changing field equipment. Introduction Operating a national power system means managing one of the most complex… Read more
-

Improving and evaluating prediction intervals
Using artificial intelligence and statistical methods for prediction the future is very helpful, but not always easy to understand. The ways that models decide on a prediction can be difficult to comprehend for humans. Therefore, it might be difficult to trust a model to make the right decisions, especially if the model is used for… Read more
-

Do you wish you could learn how to automate power grid operation, increase transfer capacity, predict transformer failure, and more in one day? – Data Science at #techday
On Tuesday April 27th Statnett and Elhub hosted the sixth annual TechDay, the Norwegian energy sector’s very own IT-conference. Both representatives from the hosts and several other actors in the business were present. Developers, testers, system- and solution-architects, and many more who work with IT systems gathered to share ideas and present their work at… Read more
-
Science-backed techniques to improve your data visualizations, part 1
A picture is worth a thousand words. But how do you make sure your plots are saying the rights words? Read more