Skip to content
Data Science @ Statnett
Home
Contact
About us
Search
Author:
Gerben Dekker
April 27, 2018
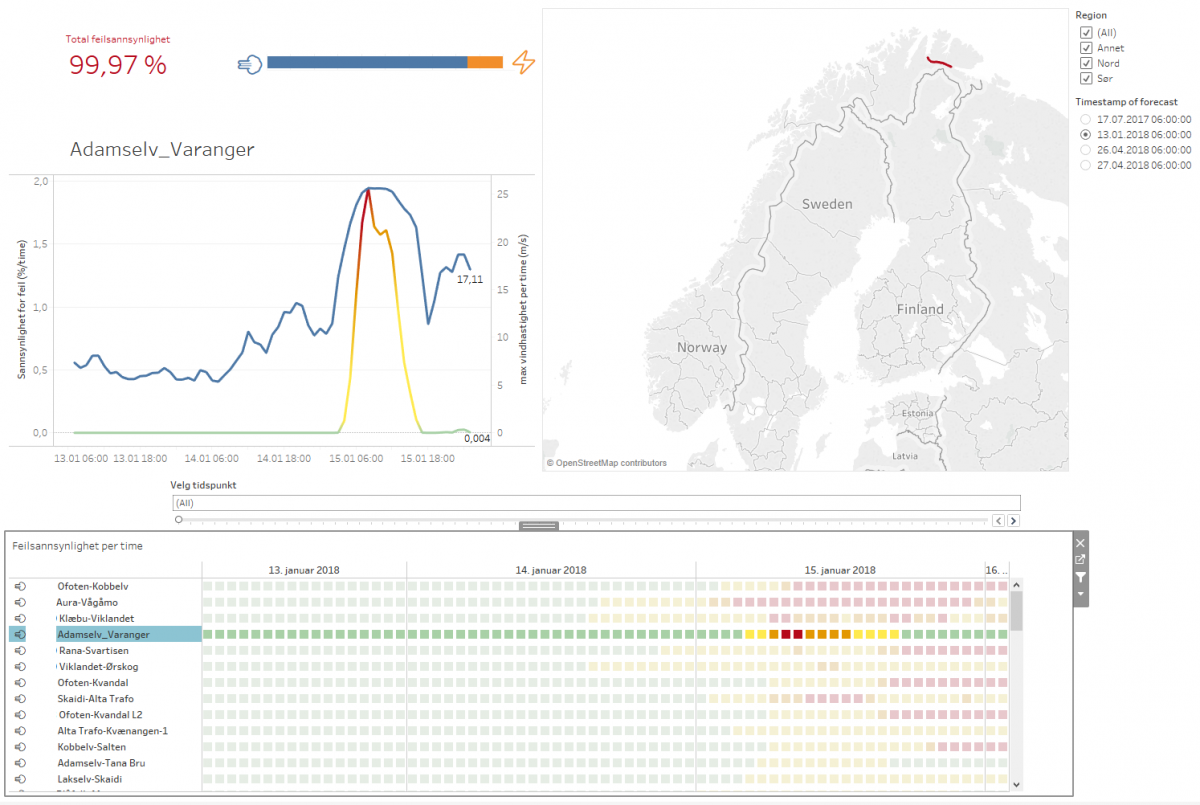
Setting up a forecast service for weather dependent failures on power lines in one week and ten minutes
Gerben Dekker
Loading Comments...
Write a Comment...
Email (Required)
Name (Required)
Website