
Welcome to the blog for Data Science in Statnett, the Norwegian electricity transmission system operator. We use data science to extract knowledge from the vast amounts of data gathered about the power system and suggest new data-driven approaches to improve power system operation, planning and maintenance. In this blog, we write about our work. Today’s topic is a model for estimating the probability of failure of overhead lines.
Knowing the probability of failure is central to reliability management
For an electricity transmission system operator like Statnett, balancing power system reliability against investment and operational costs is at the very heart of our operation. However, a more data-driven approach can improve on the traditional methods for power system reliability management. In the words of the recently completed research project Garpur:
Historically in Europe, network reliability management has been relying on the so-called “N-1” criterion: in case of fault of one relevant element (e.g. one transmission system element, one significant generation element or one significant distribution network element), the elements remaining in operation must be capable of accommodating the new operational situation without violating the network’s operational security limits.
Today, the increasing uncertainty of generation due to intermittent energy sources, combined with the opportunities provided e.g. by demand-side management and energy storage, call for imagining new reliability criteria with a better balance between reliability and costs.
In such a framework, knowledge about failure probabilities becomes central to power system reliability management, and thus the whole planning and operation of the power system. When predicting the probability of failure, weather conditions play an important part; In Norway, about 90 percent of all temporary failures on overhead lines are due to weather, the three main weather parameters influencing the failure rate being wind, lightning and icing. In this post, we present a method to model the probability of failures on overhead lines due to lightning. The full procedure is documented in a paper to PMAPS 2018. In an upcoming post we will demonstrate how this knowledge can be used to predict failures using weather forecast data from met.no.
Data sources: failure statistics and weather data
Statnett gathers failure statistics and publishes them annually in our failure statistics. These failures are classified according to the cause of the failure. For this work, we considered 102 different high voltage overhead lines. For these there have been 329 failures due to lightning in the period 1998 – 2014.
We have used renanalysis weather data computed by Kjeller Vindteknikk. These reanalysis data have been calculated in a period from january 1979 until march 2017 and they consist of hourly historical time series for lightning indices on a 4 km by 4 km grid. The important property with respect to the proposed methods, is that the finely meshed reanalysis data allows us to use the geographical position of the power line towers and line segments to extract lightning data from the reanalysis data set. Thus it is possible to evaluate the historical lightning exposure of the transmission lines.
Lightning indices
The first step is to look at the data. Lightning is sudden discharge in the atmosphere caused by electrostatic imbalances. These discharges occur between clouds, internally inside clouds or between ground and clouds. There is no atmospheric variable directly associated with lightning. Instead, meteorologists have developed regression indices that measure the probability of lightning. Two of these indices are linked to the probability of failure of an overhead line. The K-index and the Total Totals index. Both of these indices can be calculated from the reanalysis data.

Figure 1 shows how lightning failures are associated with high and rare values of the K and Total Totals indices, computed from the reanalysis data set. For each time of failure, the highest value of the K and Total Totals index over the geographical span of the transmission line have been calculated, and then these numbers are ranked among all historical values of the indices for this line. This illustrates how different lines fail at different levels of the index values, but maybe even more important: The link between high index values and lightning failures is very strong. Considering all the lines, 87 percent of the failures classified as “lightning” occur within 10 percent of the time. This is promising…

In Norway, lightning typically occurs during the summer in the afternoon as cumulonimbus clouds accumulate during the afternoon. But there is a significant number of failures due to thunderstorms during the rest of the year as well, winter months included. To see how the indices, K and T T , behave for different seasons, the values of these two indices are plotted at the time of each failure in Figure 3. From the figure it is obvious, though the data is sparse, that there is relevant information in the Total Totals index that has to be incorporated into the probability model of lightning dependent failures. The K index has a strong connection with lightning failures in the summer months, whereas the Totals Totals index seems to be more important during winter months.
Method in brief
The method is a two-step procedure: First, a long-term failure rate is calculated based on Bayesian inference, taking into account observed failures. This step ensures that lines having observed relatively more failures and thus being more error prone will get a relatively higher failure rate. Second, the long-term annual failure rates calculated in the previous step are distributed into hourly probabilities. This is done by modelling the probabilities as a functional dependency on relevant meteorological parameters and assuring that the probabilities are consistent with the failure rates from step 1.
Bayesian update
From the failure statistics we can calculate a prior failure rate 
When we observe a particular line, the failures arrive in what is termed a Poisson process. When we assume that the failure rate is exponentially distributed, we arrive at a convenient expression for the posterior failure rate 

Where 


expectations.
Distributing the long term failure rates over time
We now have the long-term failure rate for lightning, but have to establish a connection between the K-index, the Totals Totals index and the failure probability. The goal is to end up with hourly failure probabilities we can use in monte-carlo simulations of power system reliability.
The dataset is heavily imbalanced. There are very few failures (positives), and the method has to account for this so we don’t end up predicting a 0 % probability all the time. Read a good explanation of learning from imbalanced datasets in this kdnuggets blog.
Many approaches could be envisioned for this step, including several variants of machine learning. However, for now we have settled on an approach using fragility curves which is also robust for this type of skewed/biased dataset.
A transmission line can be considered as a series system of many line segments between towers. We assume that the segment with the worst weather exposure is representable for the transmission line as a whole.
We then define the lightning exposure at time 
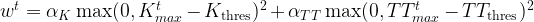
Where 



Each line then has an probability of failure at time
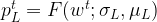
where 
To find the standard deviation and expected value that describe the log normal function, we minimize the following equation to ensure that the expected number of failures equals the posterior failure rate:

where
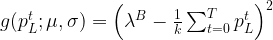
If you want to delve deeper into the maths behind the method we will present a paper at PMAPS 2018.
Fitting the model to data
In this section simulation results are presented where the models have been applied to the Norwegian high voltage grid. In particular 99 transmission lines in Norway have been considered, divided into 13 lines at 132 kV, 2 lines at 220 kV, 60 lines at 300 kV and 24 lines at 420 kV. Except for the 132 and 220 kV lines, which are situated in Finnmark, the rest of the lines are distributed evenly across Norway.
The threshold parameters 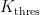
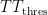

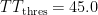

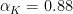

Results
The probability models presented above are being used by Statnett as part of a Monte Carlo tool to simulate failures in the Norwegian transmission system for long term planning studies. Together with a similar approach for wind dependent probabilities, we use this framework as the basic input to these Monte Carlo simulation models. In this respect, the most important part of the simulations is to have a coherent data set when it comes to weather, such that failures that occur due to bad weather appear logically and consistently in space and time.

Figure 4 shows how the probability model captures the different values of the K index and the Total Totals index as the time of the simulated failures varies over the year. This figure should be compared with figure 2. The data in Figure 4 is one out of 500 samples from a Monte Carlo simulation, done in the time period from 1998 to 2014.
The next figures show a zoomed in view of some of the actual failures, each figure showing how actual failures occur at time of elevated values of historical probabilities.







Leave a Reply